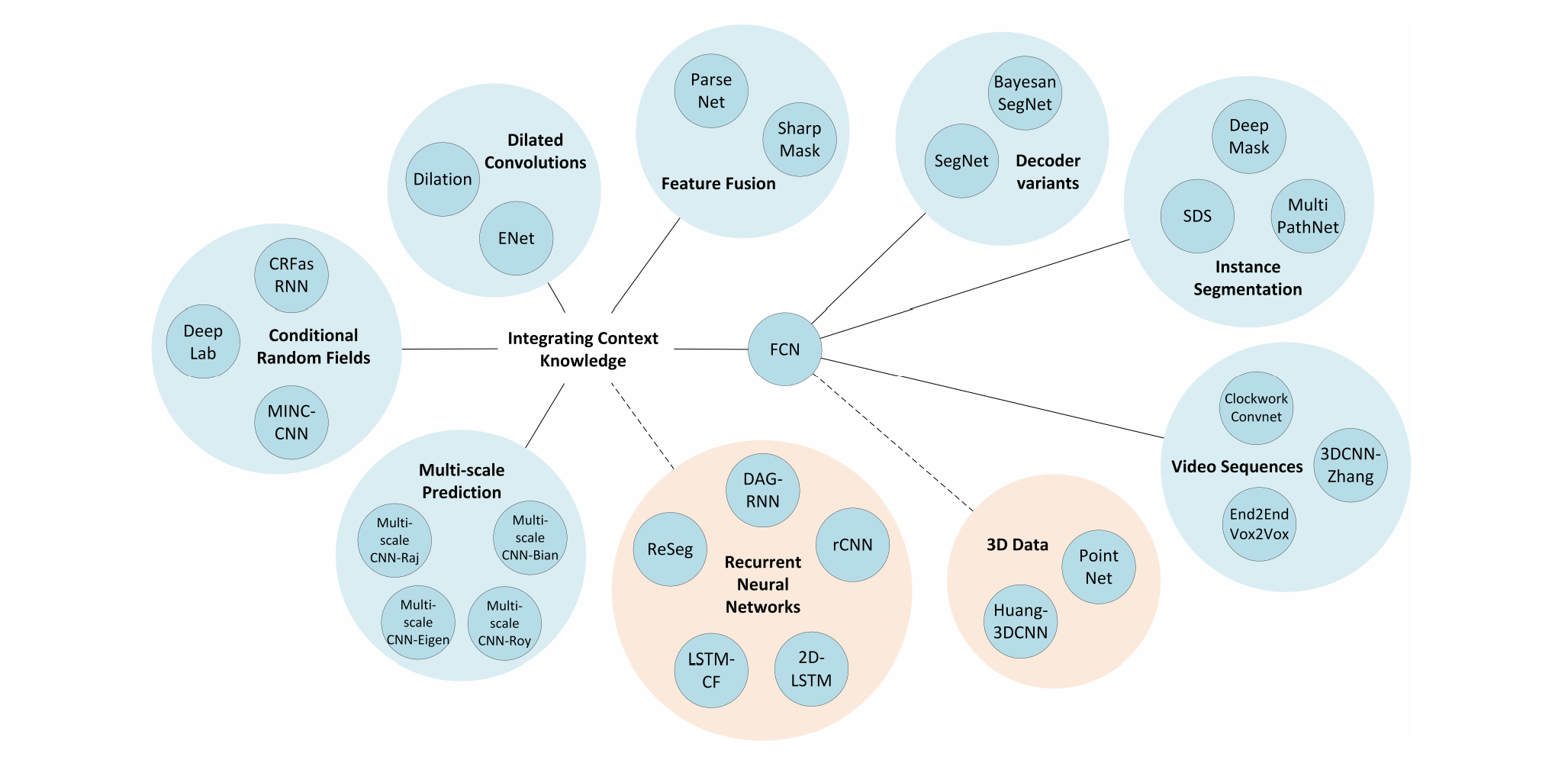
这是一篇关于综述论文的解读。原论文(A Review on Deep Learning Techniques Applied to Semantic Segmentation)
摘要:
Image semantic segmentation is more and more being of interest for computer vision and machine learning researchers. Many applications on the rise need accurate and efficient segmentation mechanisms: autonomous driving, indoor navigation, and even virtual or augmented reality systems to name a few. This demand coincides with the rise of deep learning approaches in almost every field or application target related to computer vision, including semantic segmentation or scene understanding. This paper provides a review on deep learning methods for semantic segmentation applied to various application areas. Firstly, we describe the terminology of this field as well as mandatory background concepts. Next, the main datasets and challenges are exposed to help researchers decide which are the ones that best suit their needs and their targets. Then, existing methods are reviewed, highlighting their contributions and their significance in the field. Finally, quantitative results are given for the described methods and the datasets in which they were evaluated, following up with a discussion of the results. At last, we point out a set of promising future works and draw our own conclusions about the state of the art of semantic segmentation using deep learning techniques.
我看了这篇综述受益匪浅,如果有时间的话请阅读原作。本文只是对原作阅读的粗浅笔记。
介绍分割
对图像进行分割主要有:语义分割(Semantic segmentation)和实例分割(Instance segmentation)。它们的区别一目了然:

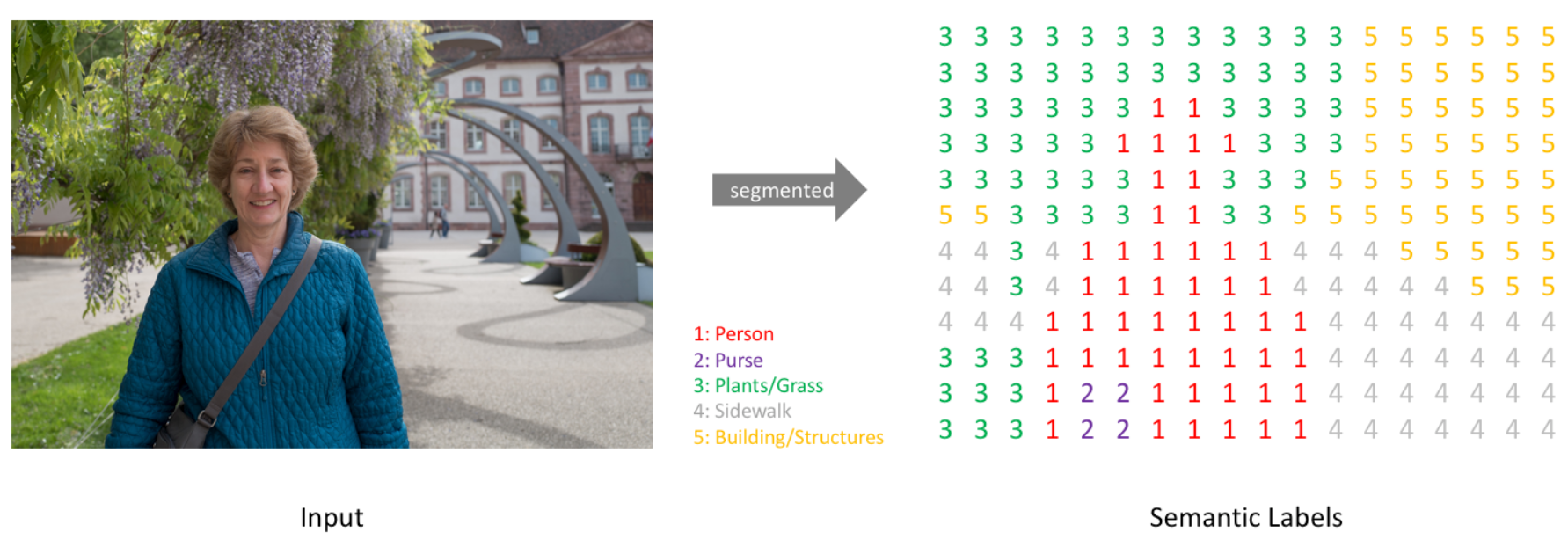
左图:原图;中图:语义分割;右图:实例分割。
很明显,语义分割希望将不同类别的物体所在位置的像素分开来,但是对于相同类别的不同物体并不敏感;而实例分割不但需要分开每一个位置上像素属于哪一类,还要分出它具体属于哪一个对象。
我们知道一个图像只不过是许多像素的集合。图像分割分类是对图像中属于特定类别的像素进行分类的过程,因此图像分割可以认为是按像素进行分类的问题。
如果你对离散数学以及softmax很敏感的化,肯定第一时间会产生这样的联想:
这张图实际上是这样的:
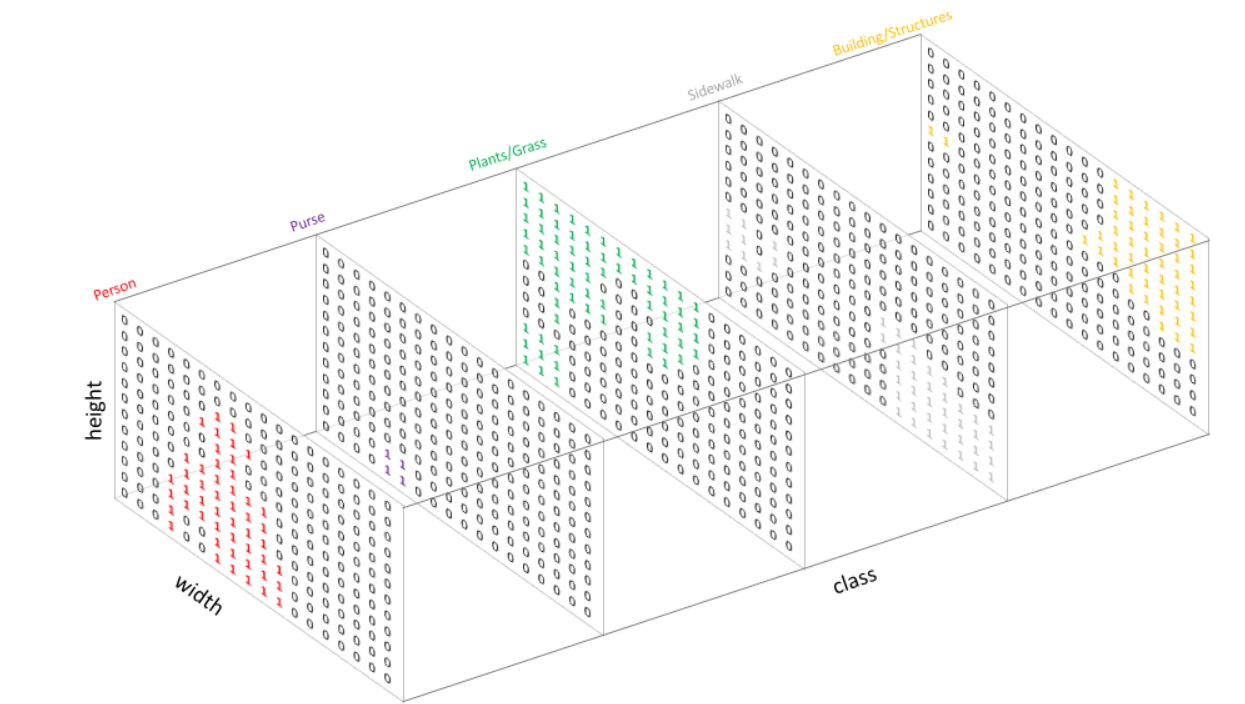
当然,对于实际应用中通道数量的具体数字可根据实际需求选择。例如,在前景分割中,仅需分割出前景和背景,因此只需要一个通道。而全景分割中,如果使用类one-hot编码,则需要有和对象数目+1一样多的通道数。
分割的技术
在深度学习方法流行之前,TextonForest和基于随机森林分类器等语义分割方法是用得比较多的方法。但是本文章的背景是基于深度学习方法的计算机视觉,所以不做过多讨论。
深度学习技术在各个计算机领域获得了巨大的成功,其解决语义分割问题可以概括为几种思路:
- 块分类(Patch classification)
- 全卷积方法(基于FCN)
- 编码器-解码器结构(encoder-decoder,本质基于FCN)
- 跨层连接的encoder-decoder结构
块分类(Patch classification)
块分类算得上是一类最古老的方法。
如其名,把图像分成小块塞给网络进行分类。分成指定大小的小块是因为全连接网络只接受指定大小的输入。这大概是最初的基于深度学习的分割方法了(吧)。
全卷积方法(基于FCN)
全卷积方法在块分类之后,优势是使用全卷积代替了块分类中的全连接。
用于代替全连接的全卷积方法除了在其他视觉方法里很出名,也很快用到了分割算法中。2014年,全卷积网络(FCN)横空出世,FCN将网络全连接层用卷积取代,因此使任意图像大小的输入都变成可能,而且速度比Patch classification方法快很多。(我用简单分类模型实测了一下也是,全连接真的是太烂了,又慢又重,但是作为多层感知机到全卷积网路中间的过度组件,还是功不可没的。)
插值法实现的上采样
在全卷积方法中,为了使输出和输入大小相同,在卷积导致特征图变小后还需要经过上采样使特征图变为原来大小。
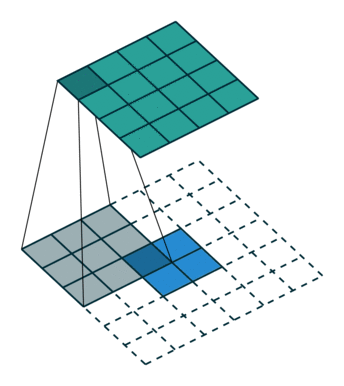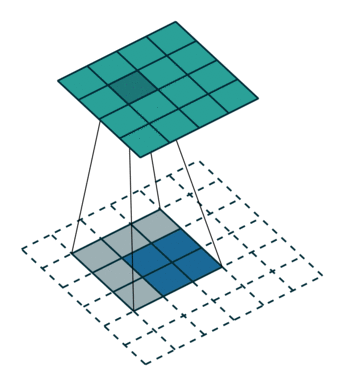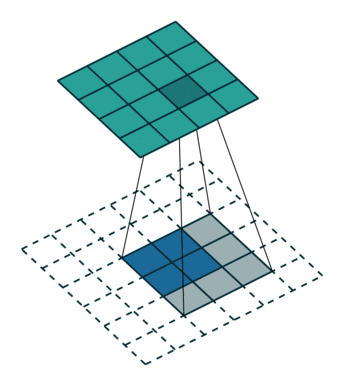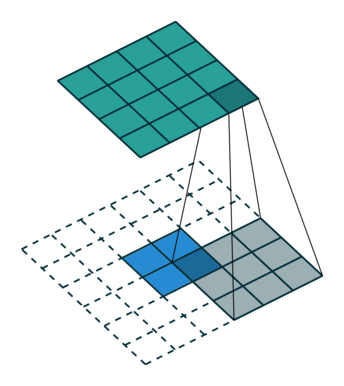
上图:一种反卷积的示意。其中蓝色较小的特征图是输入,通过在它周围填充,使其变为较大的特征图后,再进行卷积。得到的结果是绿色的特征图。
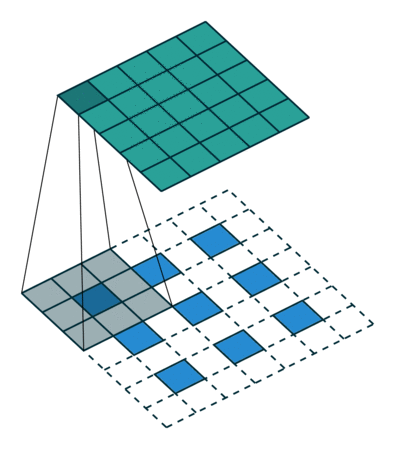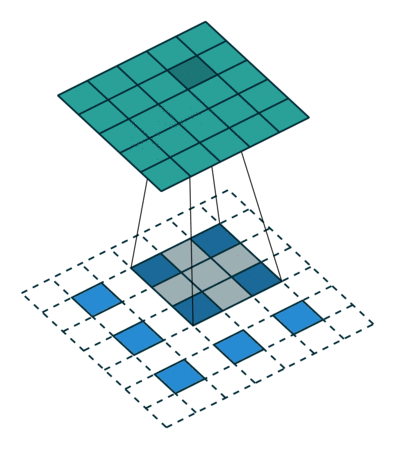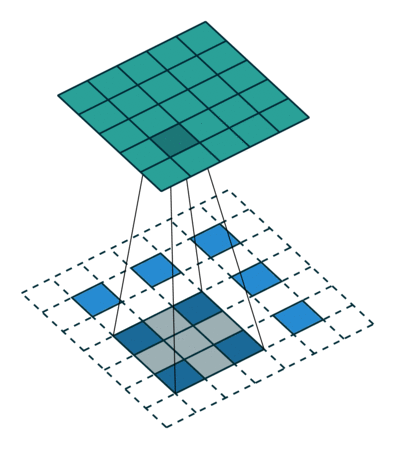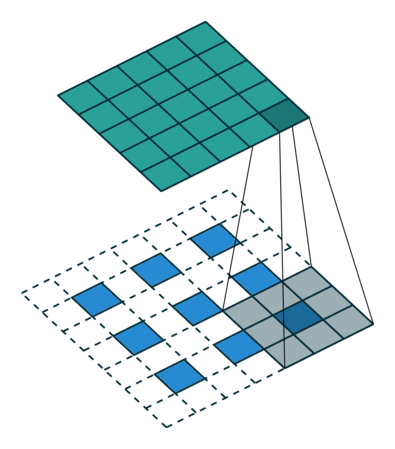
上图:另一种反卷积的示意。其中蓝色较小的特征图经过某种填充方法进行填充,变为较大的特征图后再进行卷积。
反卷积的常见思路是通过一些填充的方法将较小的特征图变大,然后通过卷积获得比原来的小特征图更大的特征图。较为常用的填充方法是插值法。
插值的方法主要可以分为两类,一类是线性图像插值方法:
- 最近邻插值(Nearest neighbor interpolation)
- 双线性插值(Bi-Linear interpolation)
- 双立方插值(Bi-Cubic interpolation)
另一类是非线性图像插值方法:
- 基于小波变换的插值算法
- 基于边缘信息的插值算法。
以上的这些方法都是一些插值方法,需要我们在决定网络结构的时候进行挑选。这些方法就像是人工特征工程一样,并没有给神经网络学习的余地,神经网络不能自己学习如何更好地进行插值,这个显然是不够理想的。
转置卷积实现的上采样
在上采样的方法中,比较出名的是转置卷积,因为它允许我们使用可学习的上采样过程。
典型的转置卷积运算将采用滤波器视图中当前值的点积并作为相应的输出位置产生的单个值,而转置卷积的过程基本想法。对于转置卷积,我们从低分辨率特征图中获取单个值,并将滤波器中的所有权重乘以该值,将加权值输出到更大的特征图。
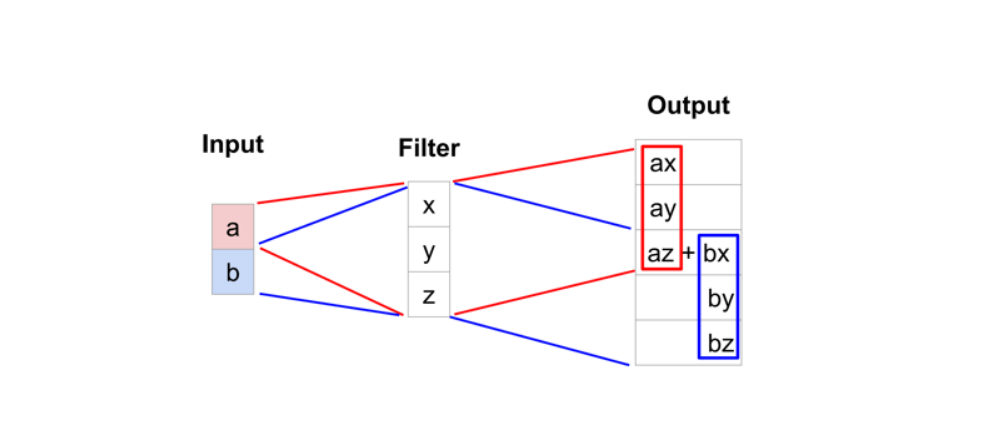
上图:转置卷积的一种示意。
Tips:神经网络中的解卷积层也被称作:转置卷积(Transposed Convolution)、上卷积(upconvolution)、完全卷积(full convolution)、转置卷积(transposed convolution)、微步卷积(fractionally-strided convolution)。
转置卷积常常在一些文献中也称之为反卷积(Deconvolution)和部分跨越卷积(Fractionally-strided Convolution),因为称之为反卷积容易让人以为和数字信号处理中反卷积混起来,造成不必要的误解,因此下文都将称为转置卷积,并且建议各位不要采用反卷积这个称呼。
编码器-解码器结构(encoder-decoder,本质基于FCN)
encoder由于pooling逐渐减少空间维度,而decoder逐渐恢复空间维度和细节信息。
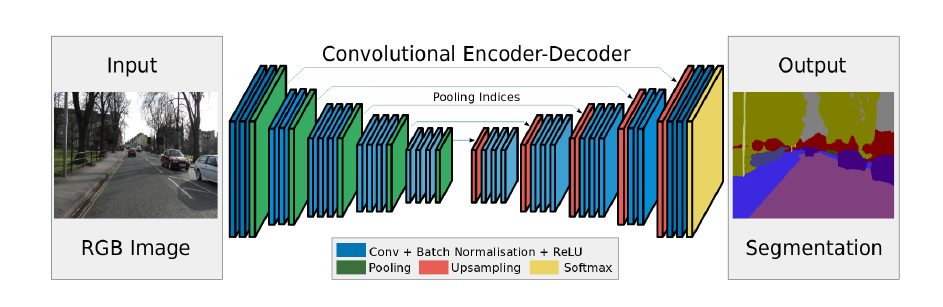
实际上,符合下采样提取特征,再上采样恢复原大小的都可以称为encoder-decoder结构。
跨层连接的encoder-decoder结构
通常从encoder到decoder还有shortcut connetction(捷径连接,也就是跨层连接,其思想我猜是从VGG跨层连接出现的思想)。
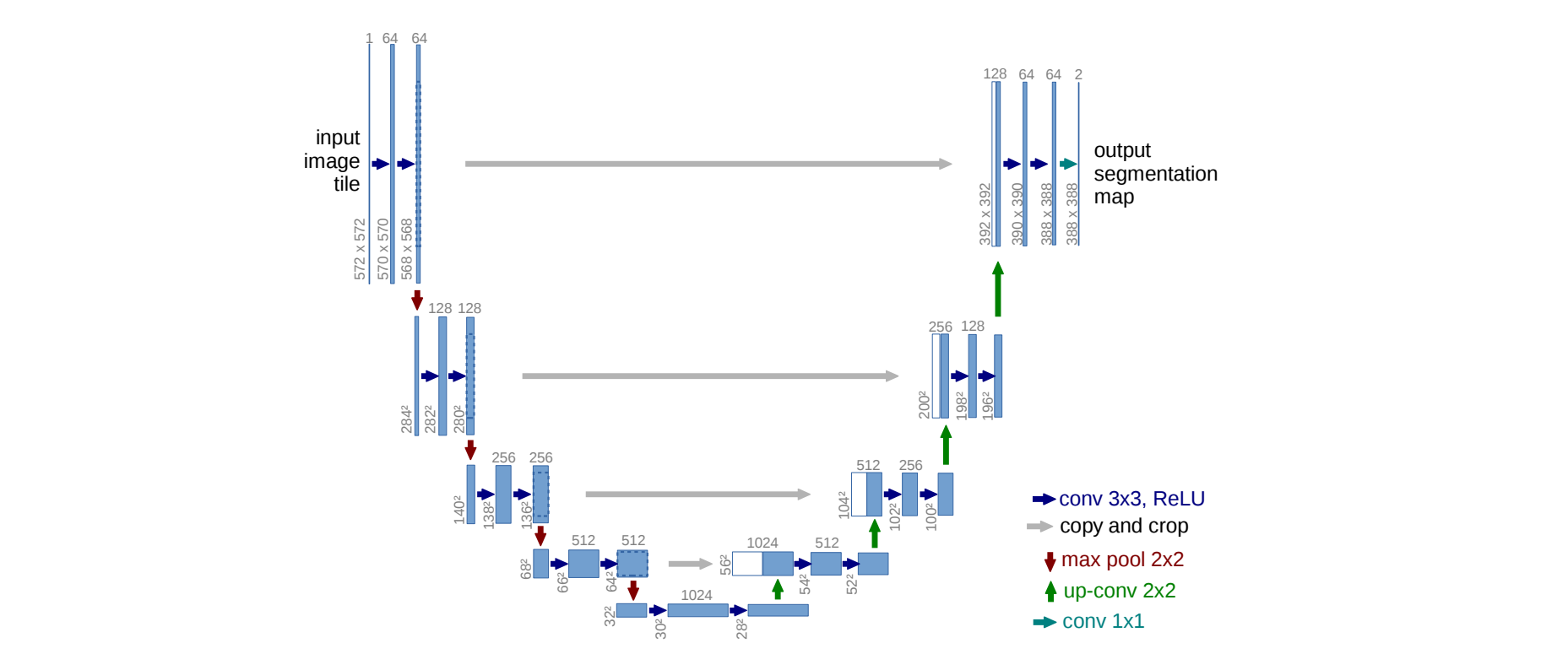
上图是带有跨层连接的encoder-decoder的代表之一:UNet的结构。
高低层特征融合
由于池化操作造成的信息损失,上采样(即使采用解卷积操作)只能生成粗略的分割结果图。因此,论文从高分辨率的特征图中引入跳跃连接(shortcut/skip connection)操作改善上采样的精细程度(感觉像是从ResNet开始出现的思想):
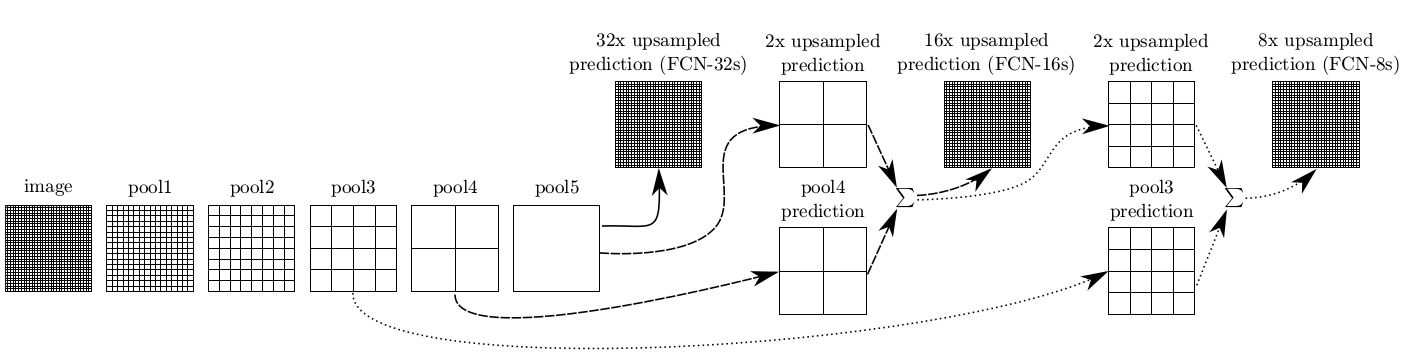
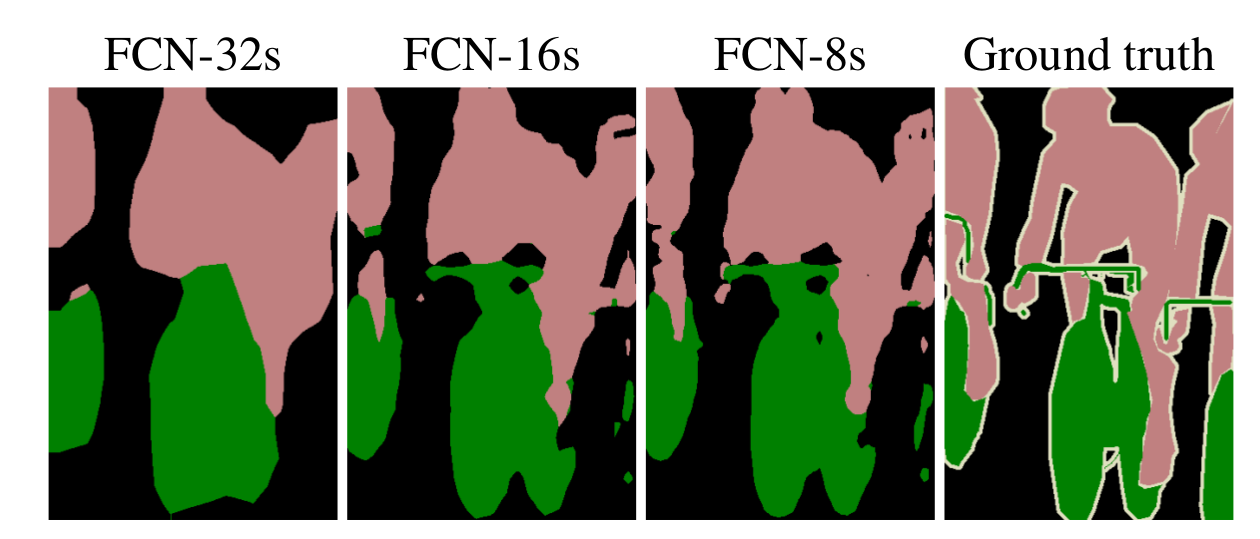
实验表明,这样的分割结果更细致更准确。在逐层fusion的过程中,做到第三行再往下,结果又会变差,所以作者做到这里就停了。可以看到如上三行的对应的结果:
空洞卷积(Dilated/Atrous Convolution,代替了“池化-上采样”的过程)
尽管FCN及encoder-decoder结构中移除了全连接层,但是CNN模型用于语义分割还存在一个问题,就是下采样操作。这里使用池化的下采样为例:pooling操作可以扩大感受野因而能够很好地整合上下文信息(context中文称为语境或者上下文,通俗的理解就是综合了更多的信息来进行决策),对high-level的任务(比如分类),这是很有效的。但同时,由于pooling下采样操作,使得分辨率降低,因此削弱了位置信息,而语义分割中需要score map和原图对齐,因此需要丰富的位置信息。
Dilated/Atrous Convolution(空洞卷积),这种结构代替了池化,一方面它可以保持空间分辨率,另外一方面它由于可以扩大感受野因而可以很好地整合上下文信息(我觉得这个设计很有意思,原图的大小完全不会改变,也不需要上采样了)。
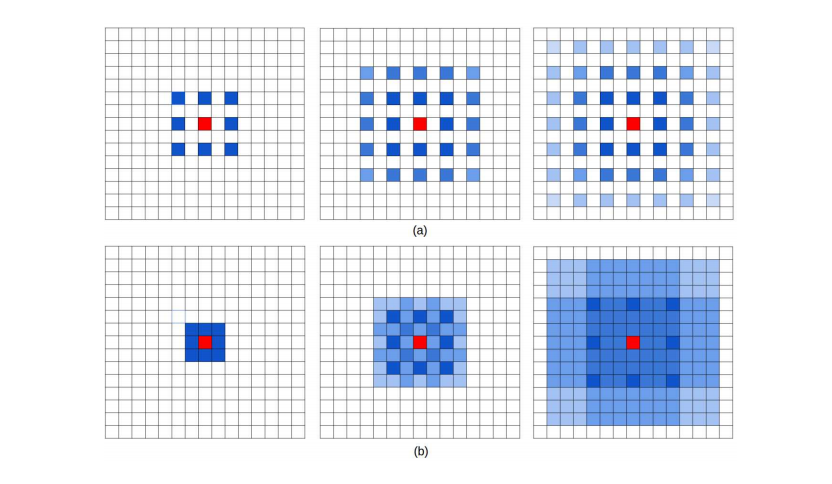
上图:在某篇论文中出现的空洞卷积示意图。
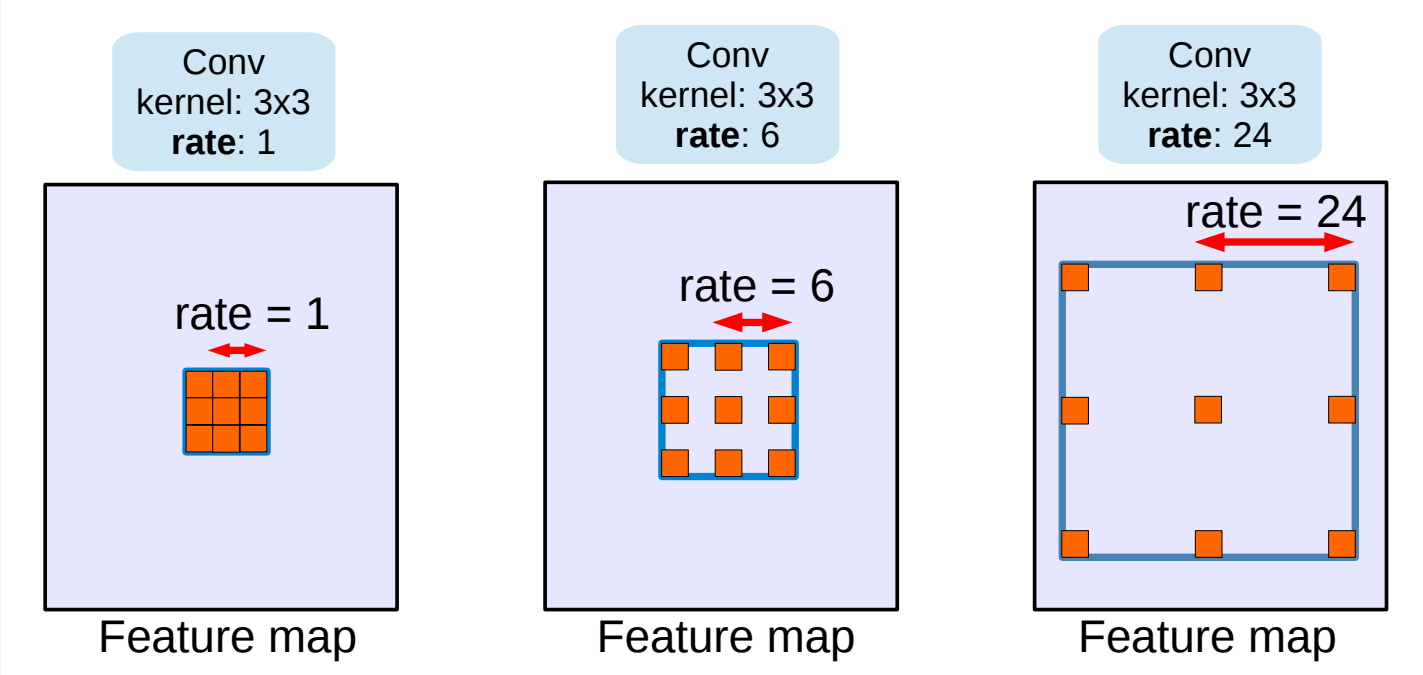
上图:另一张空洞卷积的示意图。
条件随机场
在使用全卷积网络的分割方法中,有一个很常用的基本框架:
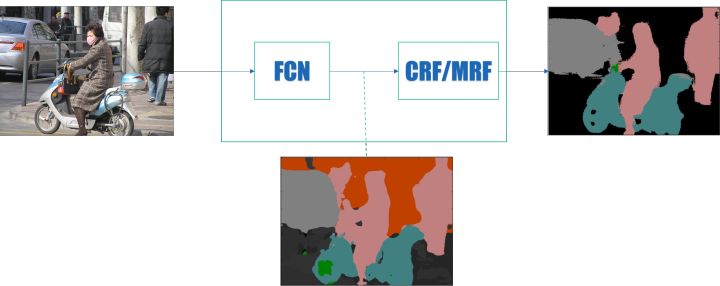
其中, FCN 表示各种全卷积网络,CRF 为条件随机场,MRF 为马尔科夫随机场。其大致思路就是前端使用 FCN 进行特征粗提取,后端使用 CRF/MRF 优化前端的输出,最后得到分割图。
条件随机场(Conditional Random Field,CRF) 后处理操作通常用于进一步改善分割的效果。CRFs 是一种基于底层图像的像素强度进行“平滑”分割(‘smooth’ segmentation)的图模型,其工作原理是相似强度的像素更可能标记为同一类别。CRFs 一般能够提升 1-2% 的精度。
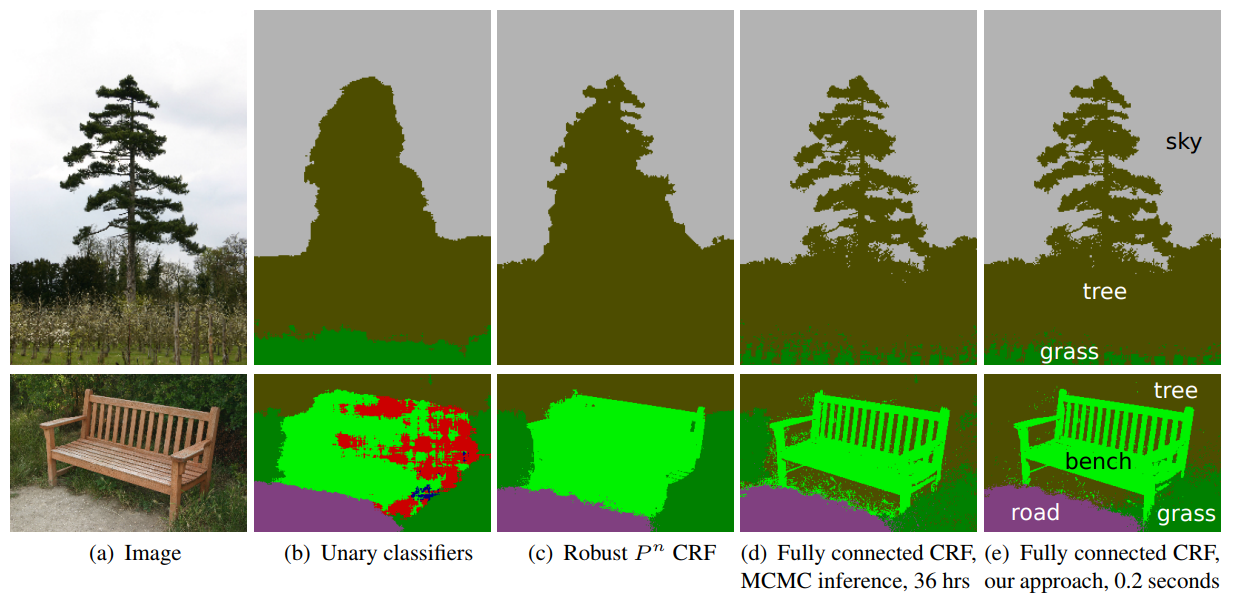
上图为CRF示意图。(b)一元分类结合CRF;(c, d, e)是CRF的变体,其中(e)是广泛使用的一种CRF。
分割的数据集
截止到原综述写作时间为止时较为流行的数据集:
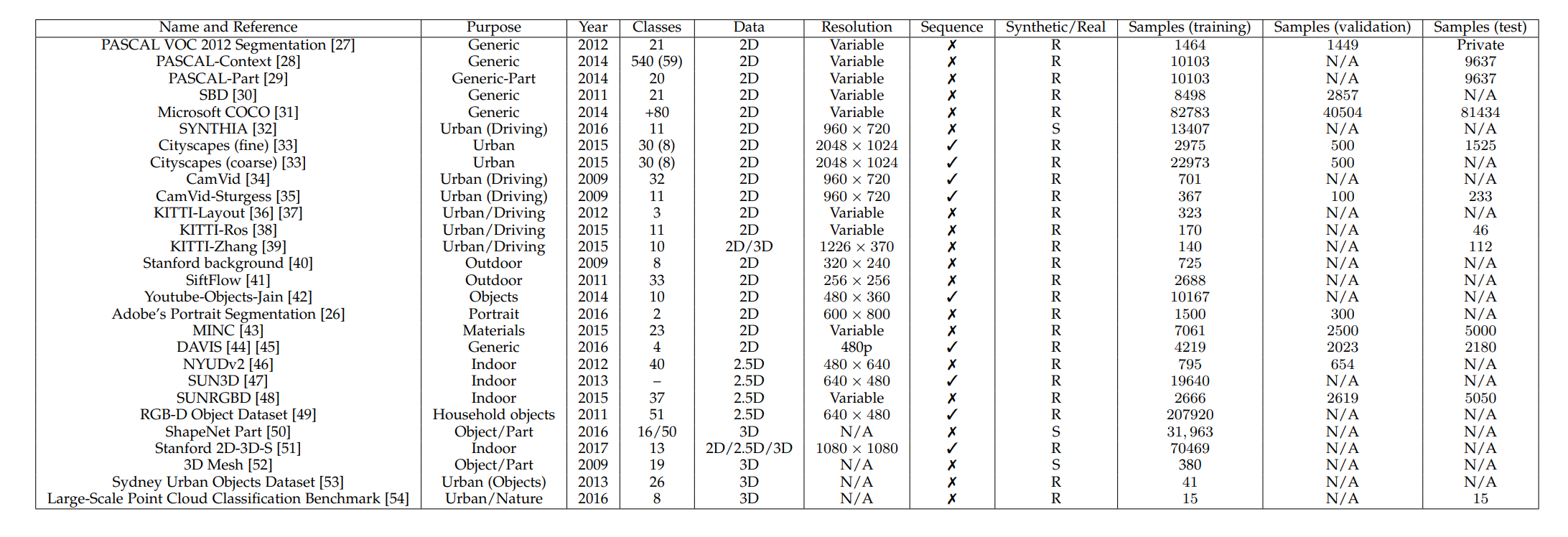
还没看完,看完就写。
领域知名论文
基于深度学习的分割方法
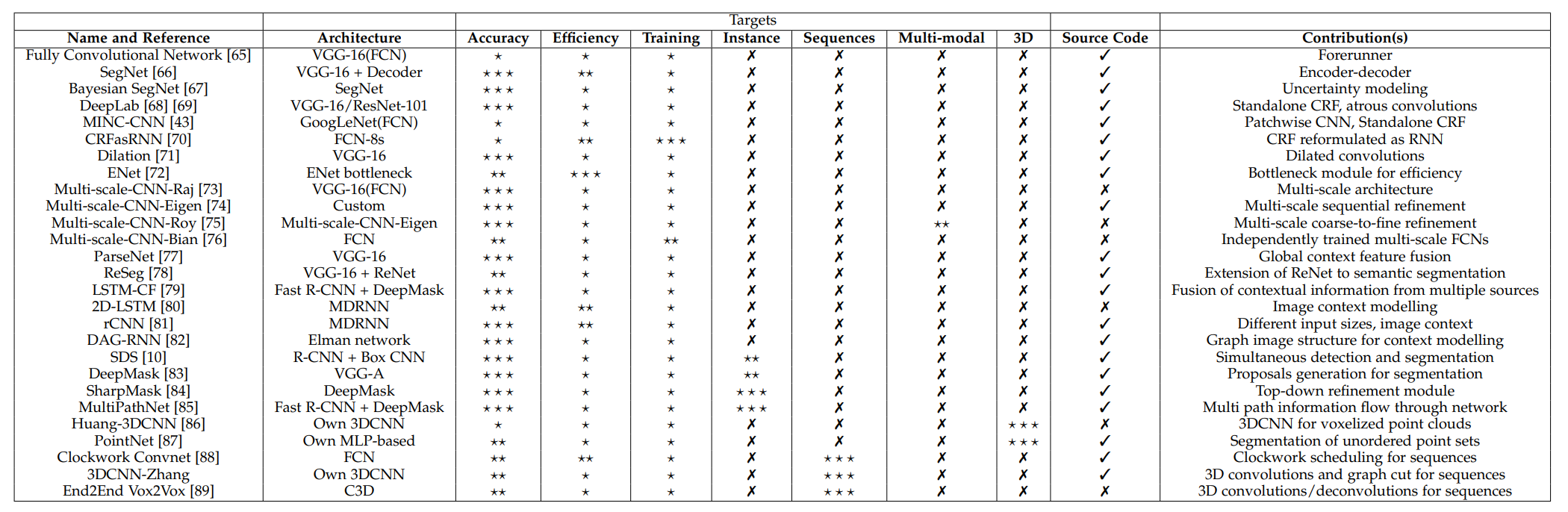
FCN
主要贡献:使端对端的卷积语义分割网络变得流行起来;通过deconvolutional layers进行上采样;通过skip connection改善了上采样的粗糙度。
SegNet
主要贡献:使用Maxpooling indices来增强位置信息。
Dilated Convolutions
主要贡献:使用空洞卷积用来进行稠密预测(dense prediction);提出上下文模块(context module),使用空洞卷积(Dilated Convolutions)来进行多尺度信息的的整合。
DeepLab (v1 & v2)
主要贡献:使用atrous卷积,也就是后来的空洞卷积,扩大感受野,保持分辨率;提出了atrous spatial pyramid pooling (ASPP),整合多尺度信息;使用全连接条件随机场(fully connected CRF)进行后处理,改善分割结果。
RefineNet
主要贡献:精心设计了encoder-decoder架构中的decoder部分,使得性能提升;整个网络的设计都遵循residual connections,网络表达能力更强,梯度更容易反向传播。
PSPNet
主要贡献:使用pyramid pooling整合context;使用auxiliary loss。
Large Kernel Matters
主要贡献:提出一种具有非常大的内核卷积的编码器-解码器体系结构。
DeepLab v3
主要贡献:改进的无孔空间金字塔池化(ASPP);级联使用atrous卷积的模块。
上述方法的关系